

Xでは今日も今日とて、「理学療法士の年収」が燃えている。

タイムラインには、だいたいこの2種類が流れてきます。
「PTって薄給すぎ。生活無理」
「いや、普通に暮らせる。文句言うな」
そして最後は、決まってこうなる。
「平均年収430万らしいよ」
「ほら、やっぱ少ないじゃん」
「いや、十分でしょ」
……で、また燃える。
でも、この議論、そもそも土台がズレています。平均“だけ”を持ち出した瞬間に、話が終わるからです。
平均430万円。
この数字が本当かどうかより大事なのは——
データの分布を意識せずに、平均を語ると大変なことになる
詳しく見ていきましょう!
データの分布とは?
年収のように、1円の2倍が2円、100円の5倍が500円になる―
―こういう「量として連続的に増減するデータ」を連続変数と呼びます。
連続変数の“本体”は、平均値そのものではなく、
値がどこに集中し、どこまで散らばっているかです。
同じ平均でも、
多くの人が平均付近に集まっているのか
一部の高額が平均を引っ張っているのか
で、見えている世界は別物になります。
だから最初に見るべきは平均ではありません。
データの分布です。
まずヒストグラム(度数分布)を出す。
そこから「山は1つか?2つか?」「歪みは?」「外れ値は?」を確認して、
やっと平均や中央値の意味が決まります。
・真ん中っぽい顔をしているだけで、実は誰もそこにいない
・少数の高年収に引っ張られて、現場の実感とズレる
・集団が混ざっていて、平均が何も代表していない
平均が語れるのは、分布を見た“後”です。
Rで「年収アンケート500人」を仮想実験してみた
今回は統計ソフトRを使って、理学療法士の集団A、B、Cに500人ずつに「年収いくら?」と聞いた、という状況をシミュレーションしました。
現実なら、
- 少し見栄を張って高めに言う
- ノーコメントが出る
- 聞き方や場の空気で回答が偏る
など、いろいろな偏り(バイアス)が混ざります。
しかし今回は、そういったものが一切ない、という理想条件にします。
その上で、分布だけを変えて「平均年収400万円」の仮想データを作成しました。
ここからが本題です。データの分布を意識しないとどのような結果になるでしょうか?
同じ平均400万円でも、分布が違えば“別世界”
下の例は、全部「平均400万円」です。
でも、グラフを並べた瞬間に分かります。
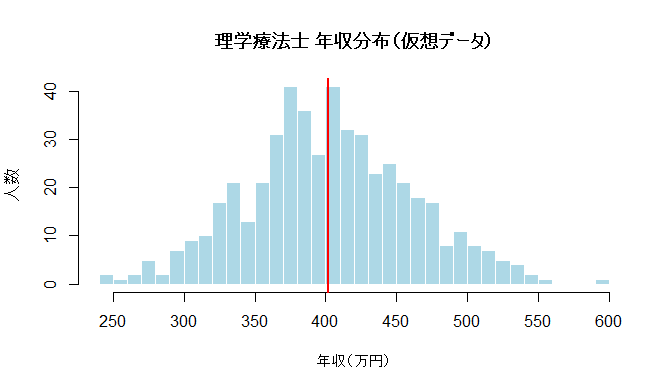
A)左右対称で、なだらかな分布(ヒストグラム①)
ヒストグラム①は、年収がある範囲にほどよく散らばりつつ、極端な値が少ないタイプです。
言い換えると、みんなが「だいたいこのへん」に集まっている。
「この年代なら、このくらい」
が半ば自動で決まり、上下に大きくブレにくいケースです。
分布はおおむね240〜550万円。
フルタイムの病院勤務を中心にした集団が想定されます。
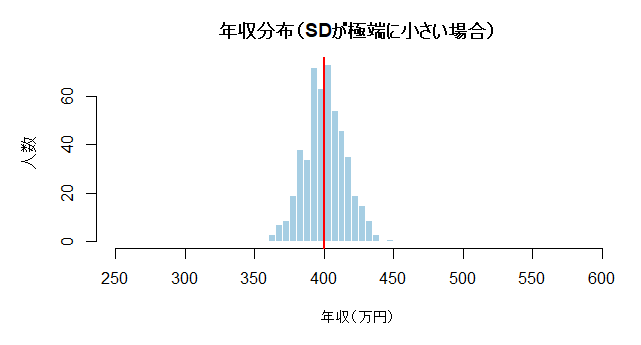
A’)分散が小さい分布(ヒストグラム②)
ここで効いてくるのが分散(ばらつき)です。
ヒストグラム②のように分散が小さいと、年収の幅が狭く、分布は360〜440万円。
先ほどでは最大550万円程度が、こちらでは440万円程度でも、平均が400万円前後になります。
このくらい狭い分布だと、
たとえば、同じ医療法人グループ内で集めた同じ給与テーブルに乗っている
役職構成が似ていて外れ値が出にくいといった背景がありそうです(※推測)。
安定志向の人には、かなり“安心できる形”。
一方で、上振れが起きにくいので、夢は小さめかもしれませんね。
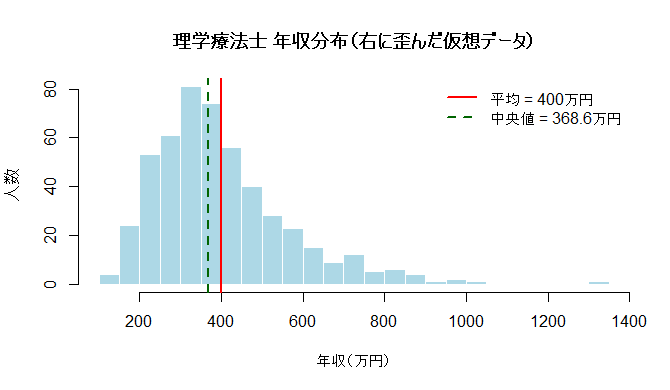
B)極端に右に歪んだ分布(ヒストグラム③)
平均が“それっぽく”見えてしまうのは、こういうときです。
Xの年収議論が一番こじれるパターンです。分布は150〜1300万円。
- 週3パート(時短・扶養内)
- 常勤(病院)
- 訪問でインセンティブ強め
- 管理職
- 研究職・大学教員
- 副業あり
みたいに、働き方も報酬体系も違う人たちを一緒にすると、上側に少数の高年収が出てきます。
すると何が起きるか。
真ん中の人(中央値)は、思ったより低いところに残ります。
一方で平均は、少数の高年収にグイッと引っ張られて上がる。
つまりこの分布では、グラフが示す通り——
中央値が平均より下になります。
平均400万円は「真ん中」ではなく、
尾っぽに持ち上げられた数字。
現場の体感が「そんなにもらってない」に寄るのは、だいたいこの構造です。
逆もあります。
パート勤務、産休・育休、病欠、時短などが多く含まれると、低い年収側に人数が寄るため、今度は平均が“それっぽく”下がります。
つまり、平均がズレるのは「高年収の尾っぽ」のときだけではありません。
“働き方の混在”があるだけで、平均は簡単にきます。
やはり厄介なのは、このズレの原因が、平均の数字だけを眺めていても分からないことです。
分布をきちんと可視化して、はじめて「何が混ざっているのか」が見えてきます。
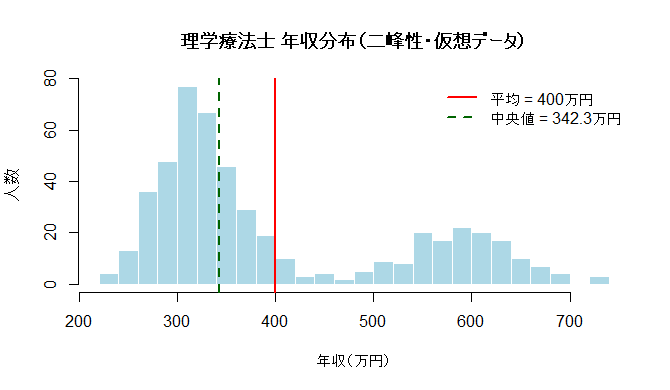
C)二峰性(山が2つの分布)も紹介します
変な形ですが、これもれっきとした平均400万円です。
でも、現場で集めたアンケートでは、もっと泥くさい理由で二峰性が生まれることがあります。
「集め方の癖」によるもの
たとえば新人向けの勉強会で、会場にいた500人にアンケートを取ったとします。
その場には、新人が多い。
一方で運営側には、役職者やベテランが混ざる。
この2つを一緒に集計すると、グラフには
「若手の山」と「役職者の山」だけがくっきり残って、
本来いるはずの“真ん中”が薄い世界が出来上がります。
「制度の段差」によるもの
・給与がなだらかに上がるのではなく、主任・係長・課長のように役職で跳ねる。
・認定資格や手当の有無でまとまって差が出る。
・常勤と非常勤で賞与や手当の設計が別世界になる。
こうした“段差”があると、分布は山が2つに割れやすくなります。
(見方によっては、これ、めちゃくちゃモチベになります。
このヒストグラムが本当なら――
なだらかに1万円ずつ上がる世界より、役職・資格・インセンティブで“段差”が用意されていることが、形として見えているからです。)
(ただし逆の読みもできます。
段差に乗れない人は途中で辞めてしまい、結果として“真ん中”が薄く見えている……という可能性もあります。
地味に効くのが「定義のズレ」によるもの
額面か手取りか、賞与込みか、残業込みか。
フルタイム換算をしているか。
ここが揃っていないだけで、山が2つに見えることがあります。
だから、二峰性を見た瞬間に言うべきは「格差だ」ではなく、まずこれです。
誰に聞いて、誰が答えて、何を年収と呼んだのか。そして、一回グラフを書いてみる。
この手順を忘れないようにしましょう!
比べるなら箱ひげ図も強い
分布を比べるとき、箱ひげ図(ボックスプロット)はかなり便利です。
ヒストグラムが「形」を見せるなら、箱ひげ図は「骨格」を見せます。
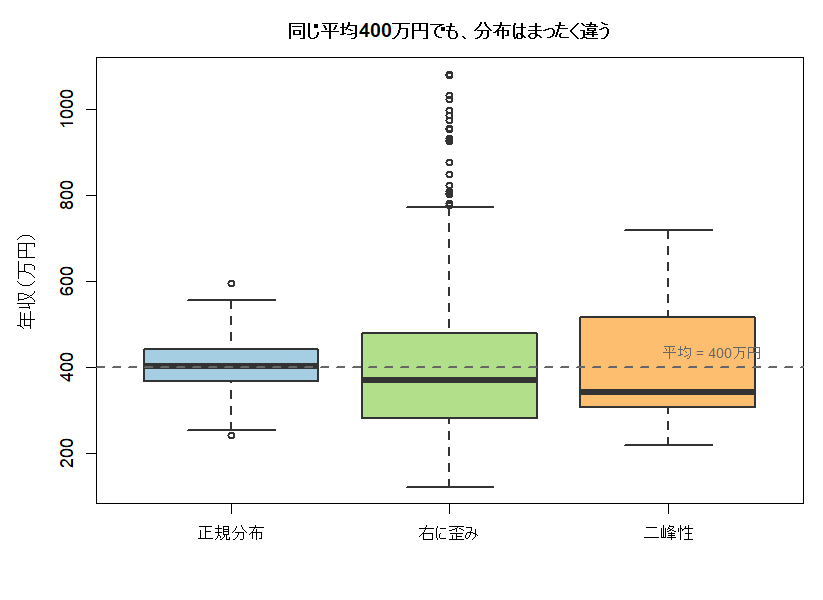
見方はシンプルです。
一番上:最大値
一番下:最小値
箱:真ん中50%(四分位範囲)
箱の下端:第一四分位
箱の上端:第三四分位
箱の中の太い線:中央値
👇四分位等の統計量について、よく理解できない方に、おすすめの書籍のリンク
同じ平均400万円で作ったデータでも、
最小値と最大値の距離が違う。
箱の大きさ(ばらつき)が違う。中央値の位置も違う。
つまり、平均は同じでも、集団の姿はまったく別物になり得ます。
簡単に「見ましょう」と言ってもすぐにはできない(ことはない!)
ここでおすすめするのは、統計ソフトRです。

xという文字に、平均400万を想定した数値を100個代入しています。
(実際は、エクセルにデータが格納されているかもしれません。)

このような数字は、目も痛くてつらいものですが、hist(x)と入力すれば、瞬間的にヒストグラムを作ってくれます。
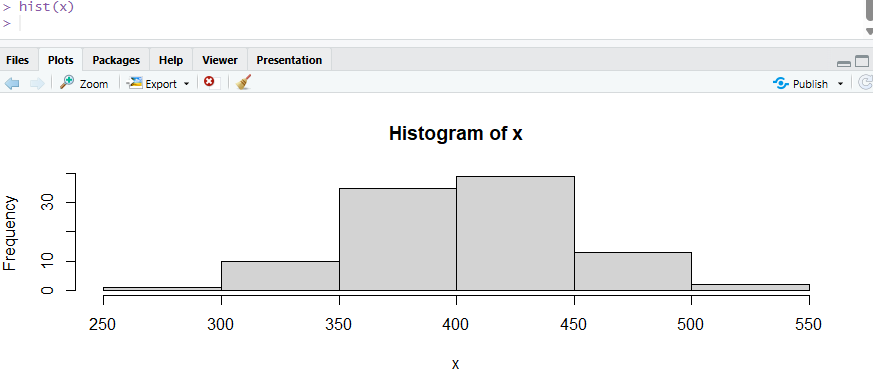
これでは、階級幅が大きすぎてよくわからないのですが、
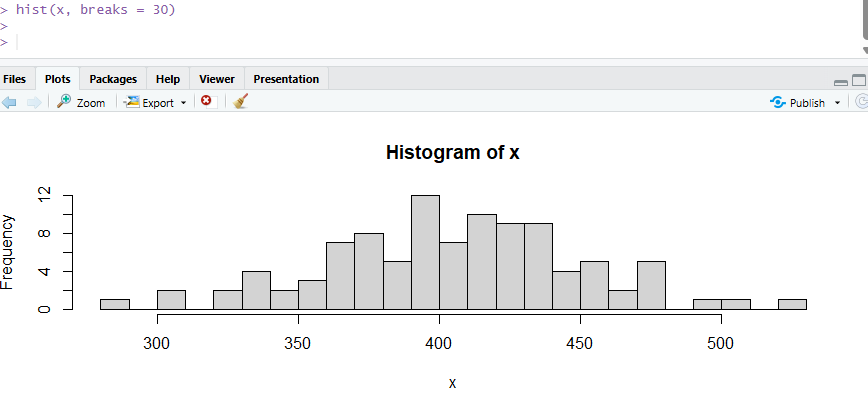
コードをわずか書き換えるだけで、hist(x, breaks = 30)と後ろに簡単なコードをひっつけると、すぐに作り替えが可能です。
さらに、連続変数であれば、summary(x)と書くだけで、最小値・最大値・平均値・中央値などをあっという間にまとめてくれます!まだ、使ったことがない人は、ぜひチャレンジをしてみてください。
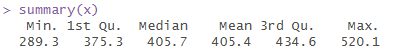
min.=最小値
1st Qu.=第一四分位
Median=中央値
Mean=平均値
3ed Qu.=第三四分位
Max.=最大値
平均に合わせて満足するのではなく、
最小値・最大値・中央値・四分位範囲まで見る。
それだけで、「この集団はどういう集団か」の解像度が一気に上がります。
まとめ
理学療法士の年収議論で「平均430万円」が出てきても、それだけでは判断できません。
平均は一点の計算結果であって、年収の現実はデータの分布にあります。
右に歪めば平均は高年収側に引っ張られ、中央値は平均より下に残る。
二峰性なら、社会の構造だけでなく、集め方(選択バイアス)でも簡単に山が2つ作られる。
平均や年収のような連続変数を手にしたら、最初にやるべきはこれです。
ヒストグラム(必要なら箱ひげ図)で可視化して、最小値・最大値・中央値・四分位範囲・標準偏差を確認する。
平均は、その後に初めて使う数字です。